

基本情報技術者試験のアルゴリズムで、探索が出てくると「線形探索と二分探索の違いは何となく分かるけど、問題になると手が止まる」と感じる人は多いです。さらにハッシュ探索まで出てくると、どれをどう使い分ければよいのか混ざりやすいですよね。
ただ、基本情報の探索アルゴリズムは、コードを丸暗記するよりも、データが並んでいるか、どこから調べるか、探索範囲をどう狭めるかを順番に見ると整理しやすくなります。科目Bでも、名前の暗記だけでなく、途中の変数や添字を追えることが大切です。
この記事では、線形探索、二分探索、ハッシュ探索の違いと、基本情報の問題で迷わない解き方をまとめます。探索アルゴリズムを「何となく苦手」で終わらせず、問題文から前提条件を読み取れる状態を目指しましょう。
- 線形探索・二分探索・ハッシュ探索の違いがわかる
- 探索アルゴリズムごとの前提条件を整理できる
- 科目Bで添字と探索範囲を追う手順がわかる
- 比較回数や計算量をざっくり判断できる
基本情報の探索アルゴリズムの種類
探索はデータを見つける処理
探索アルゴリズムとは、データの集合から目的の値を探すための手順です。名簿から名前を探す、商品一覧からIDを探す、配列から指定された数値を探す、といった処理をイメージすると分かりやすいかなと思います。基本情報では、単に「見つかったかどうか」だけでなく、どの順番で調べるか、何回くらい比較するか、見つからなかった場合にどう終了するかまで問われます。
IPAの基本情報技術者試験シラバスでは、アルゴリズムとプログラミングの範囲に代表的なアルゴリズムが含まれます。出題範囲の最新資料はIPA公式の試験要綱・シラバスページで確認できます。探索は、配列、リスト、ソート、ハッシュ表などとセットで理解すると、科目Bの問題にもつながりやすい分野です。
最初に押さえたいのは、探索方法ごとに「使える条件」が違うことです。線形探索はデータが整列されていなくても使えます。二分探索は、原則としてデータが昇順や降順に整列されている必要があります。ハッシュ探索は、キーから格納位置を求める仕組みが前提です。この前提条件を無視すると、問題文では正しい選択肢を選びにくくなります。
アルゴリズム全体の勉強順で迷う場合は、まず総論として基本情報のアルゴリズム対策と科目Bの解き方を押さえ、そのあと探索、ソート、再帰、データ構造のようにテーマ別へ分けると進めやすいです。総論記事では広く扱い、この記事では探索だけに絞って深掘りします。
| 探索方法 | 主な前提 | 見るポイント |
|---|---|---|
| 線形探索 | 整列されていなくても使える | 先頭から順に比較する |
| 二分探索 | 整列済みのデータが必要 | 中央を見て範囲を半分にする |
| ハッシュ探索 | キーから位置を計算する | 衝突時の処理も確認する |
線形探索は順に調べる
線形探索は、データを先頭から順番に調べて、目的の値と一致するかを確認する方法です。配列の1番目、2番目、3番目と進み、一致した時点で探索を終了します。もし最後まで見ても一致しなければ、目的の値は存在しないと判断します。考え方はとても単純なので、基本情報の探索アルゴリズムの中では最初に理解しやすい方法です。
線形探索の強みは、データが整列されていなくても使えることです。たとえば「8, 3, 10, 5, 1」のようにバラバラに並んでいる配列でも、先頭から順に見ていけば目的の値を探せます。事前に並べ替える必要がないため、データ数が少ない場合や、一度だけ探せばよい場合には扱いやすいです。
一方で、データ数が多くなると効率は悪くなりやすいです。最悪の場合、最後の要素まで見ないと見つからないか、最後まで見ても見つからないからです。データがn個あるなら、最大でn回の比較が必要になります。基本情報では、この「最大で全部見る」という感覚を持っておくと、二分探索やハッシュ探索との比較がしやすくなります。
- 先頭から1つずつ比較する
- 整列されていないデータにも使える
- 見つかった時点で終了できる
- 最悪の場合はすべての要素を確認する
科目Bで線形探索が出るときは、ループの終了条件を丁寧に見るのが大切です。「一致したら終了する」のか、「最後まで調べてから結果を返す」のかで、変数の値や比較回数が変わります。また、添字が0から始まるのか1から始まるのかもミスしやすいですね。単純なアルゴリズムほど油断して、最初の位置や最後の位置を1つずらしてしまうことがあります。
二分探索は半分に絞る
二分探索は、整列済みのデータに対して、中央の値を見ながら探索範囲を半分ずつ狭める方法です。たとえば昇順に並んだ配列で目的の値を探す場合、まず中央の値を確認します。目的の値が中央より小さければ左側だけを探し、中央より大きければ右側だけを探します。この判断を繰り返すことで、探す範囲が一気に小さくなります。
二分探索で最も大事な前提は、データが整列されていることです。整列されていないデータで中央を見ても、「左側に小さい値がある」「右側に大きい値がある」と判断できません。つまり、二分探索は速い代わりに、あらかじめ並び順が整っている必要があります。問題文に「昇順に格納されている」「降順に整列済み」と書かれているかを最初に探しましょう。
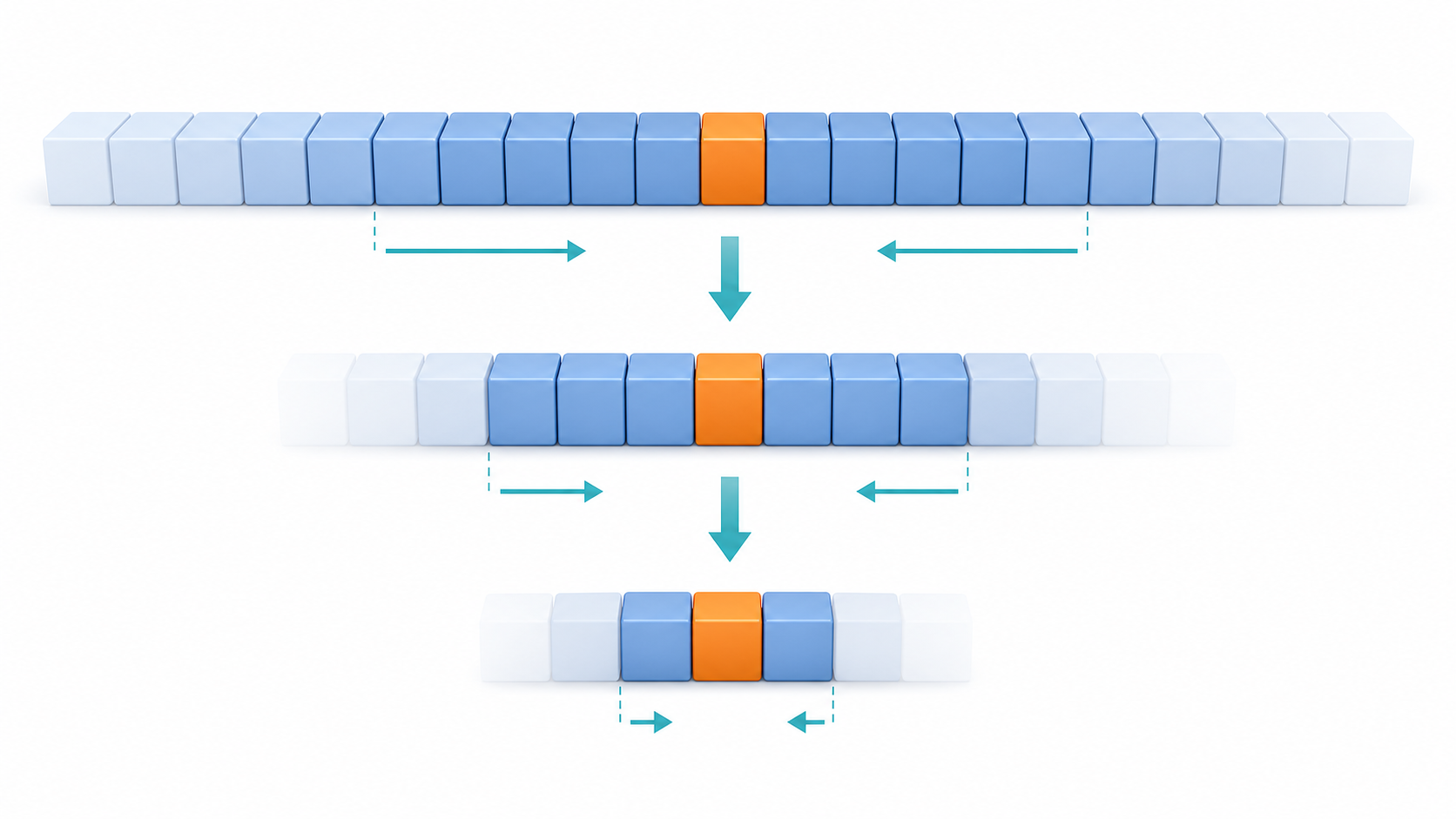
科目Bでは、二分探索の擬似言語で、左端、右端、中央の添字がどう変わるかを問われやすいです。よくある変数名で言えば、left、right、midの3つですね。midの値を求め、目的の値と比較し、次にleftまたはrightを更新します。ここで更新方向を逆に読むと、探索範囲が間違ってしまいます。
| 比較結果 | 次に探す範囲 | 更新の考え方 |
|---|---|---|
| 目的値が中央より小さい | 左側 | 右端を中央の手前へ動かす |
| 目的値が中央より大きい | 右側 | 左端を中央の次へ動かす |
| 目的値と中央が等しい | 探索終了 | 見つかった位置を返す |
比較回数のイメージも押さえておきましょう。二分探索では、1回比較するたびに候補がだいたい半分になります。データが16個なら、16、8、4、2、1のように絞れます。線形探索のように最大16個すべてを見るのではなく、少ない回数で目的の値に近づけるのが特徴です。厳密な式を暗記するより、半分ずつ候補が減る感覚を持つ方が問題では使いやすいです。
ハッシュ探索は位置を計算する
ハッシュ探索は、キーから格納場所を計算して、目的のデータへ近道する方法です。たとえば社員番号や商品コードのようなキーを、ハッシュ関数と呼ばれる計算ルールに通して、配列のどの位置を見るかを決めます。うまくいけば、先頭から順に探す必要がなく、目的の場所へ直接近い位置から確認できます。
ハッシュ探索の強みは、平均的には高速に探せることです。線形探索のように順に全部見るのではなく、キーから位置を求めるため、データ数が増えても探索回数が増えにくいです。ただし、いつでも必ず1回で終わると考えるのは危険です。異なるキーから同じハッシュ値が出ることがあり、これを衝突と呼びます。
衝突が起きた場合は、同じ場所に複数のデータをつなげて管理したり、別の空き場所を探したりします。基本情報では、ハッシュ関数そのものの難しい設計よりも、ハッシュ値、格納位置、衝突、チェイン法、オープンアドレス法のような考え方が問われやすいです。用語だけでなく、衝突した後にどの順番で確認するかを見られると安心です。
ハッシュ探索は平均的には高速ですが、衝突が多いと確認回数が増えます。試験では「衝突時の処理」を読み飛ばさないことが大切です。
線形探索や二分探索と比べると、ハッシュ探索は実装の仕組みが少し抽象的です。そのため、問題文で「キーをハッシュ関数に入力する」「剰余を使って格納位置を求める」「同じ位置になった場合はリストにつなぐ」といった表現を見つけると判断しやすくなります。目的の値を探すというより、目的の値がある場所を計算で推定する、と考えると整理しやすいですね。
比較回数をざっくり見る
探索アルゴリズムを比べるときは、細かいコードよりも、データ数が増えたときに比較回数がどう増えるかを見ると分かりやすいです。線形探索は、最悪の場合すべての要素を見るので、データ数が増えるほど比較回数もそのまま増えます。二分探索は、比較するたびに候補を半分にするので、増え方がかなり緩やかです。
ハッシュ探索は、平均的にはキーから場所を計算して少ない回数で見つけられます。ただし、衝突が多い場合や、ハッシュ表の設計が悪い場合は、追加の確認が必要になります。基本情報では、計算量の厳密な証明まで求められることは少ないですが、「どれがデータ数に比例して増えやすいか」「どれが前提条件つきで速いか」はよく問われます。
| 探索方法 | 比較回数の目安 | 向いている場面 |
|---|---|---|
| 線形探索 | 最大でn回 | データが少ない、未整列 |
| 二分探索 | おおむねlog n回 | 整列済みで大量データ |
| ハッシュ探索 | 平均的に少ない | キーで直接探したい |
ここで注意したいのは、速いアルゴリズムが常に正解とは限らないことです。二分探索は整列済みでなければ使いにくいですし、ハッシュ探索はハッシュ表を用意する必要があります。1回だけ少量のデータを探すなら、線形探索の方がシンプルで十分な場合もあります。試験でも、前提条件と目的を合わせて判断する問題が出やすいです。
また、計算量の記号だけを丸暗記するより、具体例で考える方が記憶に残ります。データが32個あるとき、線形探索なら最大32回見る可能性があります。二分探索なら、32、16、8、4、2、1と絞れるので、比較の増え方がかなり違います。この差を自分の手で1回書いてみると、科目Bの選択肢でも判断しやすくなります。
基本情報の探索アルゴリズムの解き方

問題文で前提を探す
基本情報の探索アルゴリズム問題を解くときは、いきなり擬似言語を追うより、まず問題文の前提条件を探すのがおすすめです。データは整列済みなのか、配列なのかリストなのか、キーは何なのか、見つからない場合は何を返すのか。この情報を拾ってからコードを見るだけで、かなり読みやすくなります。
特に二分探索では、整列順と比較方向が重要です。昇順なら、目的値が中央より小さいときは左側を探します。降順なら逆の考え方になります。問題文に「昇順」「降順」「小さい順」「大きい順」と書かれている場合は、必ず線を引くつもりで確認しましょう。ここを読み落とすと、leftとrightの更新を逆に考えてしまいます。
- データは整列されているか
- 添字は0始まりか1始まりか
- 探す値は数値か文字列かキーか
- 見つからないときの戻り値は何か
線形探索なら、開始位置と終了条件を見ます。ハッシュ探索なら、ハッシュ関数で求める値と、衝突時の動きを見ます。探索アルゴリズムの名前が分からなくても、問題文の前提を拾えれば「これは順番に見る問題だな」「これは中央を見て範囲を狭める問題だな」と判断できます。
科目Bの問題は文章量が多く見えるため、焦ってコード部分から読みたくなります。しかし、探索の問題では、前提条件がそのまま解法のヒントになっていることが多いです。整列済みなら二分探索、未整列でも探せるなら線形探索、キーから位置を求めるならハッシュ探索、と最初に分類できるだけでも、読む負担はかなり下がります。
さらに、戻り値の仕様も見落とさないようにしましょう。見つかった位置を返すのか、見つかったかどうかの真偽値を返すのか、見つからないときに-1のような値を返すのかで、最後に選ぶ答えが変わります。
添字と範囲を表にする
探索アルゴリズムを手で解くときは、添字と範囲を表にするのがかなり有効です。頭の中だけでleft、right、mid、iなどの変数を追うと、1回の更新で混乱しやすくなります。特に二分探索では、1回ごとに探索範囲が変わるため、表にして「今どこを見ているか」を残すだけでミスを減らせます。
表にする項目は、最初から多くしすぎなくて大丈夫です。線形探索なら、i、配列の値、比較結果の3列で十分です。二分探索なら、left、right、mid、中央の値、次の範囲を書きます。ハッシュ探索なら、キー、ハッシュ値、確認する位置、衝突時の次の位置を整理します。
| 探索方法 | 表に書く変数 | 確認すること |
|---|---|---|
| 線形探索 | i、値、比較結果 | 一致した時点で止まるか |
| 二分探索 | left、right、mid | 範囲が正しく狭まるか |
| ハッシュ探索 | キー、ハッシュ値、位置 | 衝突時に次をどう見るか |
トレース表の作り方に慣れていない場合は、先に基本情報のトレース表の書き方と科目Bで迷わない手順を確認しておくと、探索問題にもそのまま使えます。探索は変数の更新が中心なので、トレース表との相性がとても良いです。
試験本番では、すべてのステップを完璧に書く時間がない場合もあります。そのときは、変化する変数だけを優先して書きましょう。線形探索ならi、二分探索ならleft・right・mid、ハッシュ探索なら確認位置です。変わらない情報まで書きすぎると時間を使うので、点に直結する変数に絞るのが現実的です。
表にするときは、1回のループで1行増やすと決めておくと安定します。途中で行の意味を変えると見返したときに混乱するので、比較前、比較結果、更新後のどれを書いているのかを自分の中でそろえておきましょう。
midの更新でミスを防ぐ
二分探索で最もミスが多いのは、midを見たあとの範囲更新です。目的の値が中央より小さいのに右側を探してしまったり、中央の次ではなく中央を含めたまま範囲を更新してしまったりします。これを防ぐには、中央の値はすでに比較済みだと考えるのがコツです。見つからなかったなら、中央そのものは次の探索範囲から外します。
昇順の配列で、目的値が中央の値より小さい場合、探すべき範囲は中央より左側です。そのため、rightをmidの手前へ動かします。目的値が中央の値より大きい場合は、leftをmidの次へ動かします。この「中央を外す」という感覚がないと、同じmidを繰り返して無限ループのような状態になることがあります。
中央を比較して一致しなかったら、中央は次の候補から外します。小さければ左側、大きければ右側という判断を、配列の並び順とセットで確認しましょう。
midの計算式にも注意が必要です。問題によっては、leftとrightの平均を小数切り捨てで求めることがあります。添字が0始まりか1始まりかでも、中央の位置が変わるように見えることがあります。試験では、式に書かれている丸め方をそのまま使い、自己流で「真ん中っぽい位置」を選ばないことが大切です。
また、終了条件もよく見てください。leftがrightを超えたら見つからなかったと判断する形もあれば、範囲が残っている間だけ繰り返す形もあります。どちらも考え方は似ていますが、最後の1要素を確認するタイミングが違って見えることがあります。選択肢問題では、この最後の1回が正誤を分けることがあります。
演習は過去問で確認
探索アルゴリズムは、読んで分かったつもりになりやすい分野です。線形探索、二分探索、ハッシュ探索の説明を読めば理解できた気がしますが、実際の問題では、配列の添字、条件分岐、ループ終了、戻り値まで同時に見なければなりません。だからこそ、最後は過去問形式で手を動かす必要があります。
演習するときは、最初からスピードを上げなくて大丈夫です。まずは1問ずつ、問題文の前提を拾い、使われている探索方法を分類し、変数を表に書いて追います。答え合わせでは、正解か不正解かだけでなく、どの時点で範囲更新を間違えたか、どの変数を見落としたかを確認しましょう。
- 最初は時間を測らずに丁寧に追う
- 間違えた問題は変数の更新だけを書き直す
- 二分探索はleft・right・midを必ず表にする
- ハッシュ探索は衝突時の確認順を復習する
過去問演習で意識したいのは、同じテーマを数問続けて解くことです。探索を1問、ソートを1問、ネットワークを1問のようにバラバラに解くより、探索だけをまとめて解く方が、共通する読み方に気づきやすくなります。特に二分探索は、何度もleft・right・midを書いているうちに、更新方向が自然に身につきます。
データ構造と一緒に出る問題も多いので、配列やリストの基礎があやふやな場合は、基本情報の配列・リスト・ポインタの違いも合わせて確認しておくと理解がつながります。探索は、どのデータ構造の上で探しているかによって、読み方が少し変わります。
慣れてきたら、1問にかける時間を少しずつ短くしていきます。本番ではすべてを丁寧に書けない場面もあるので、最終的には「前提確認」「変数表」「答えの判断」を数分で回せる状態を目指しましょう。
探索アルゴリズムまとめ
基本情報の探索アルゴリズムは、線形探索、二分探索、ハッシュ探索の3つをまず整理すると見通しが良くなります。線形探索は先頭から順に見る方法で、未整列のデータにも使えます。二分探索は整列済みのデータを半分ずつ絞る方法で、大量データでも比較回数を抑えやすいです。ハッシュ探索はキーから位置を求める方法で、衝突時の処理までセットで理解します。
試験対策としては、最初に前提条件を読むこと、添字と範囲を表にすること、midの更新方向を確認することが重要です。探索方法の名前だけを暗記しても、科目Bの擬似言語では点につながりにくいです。どの変数がいつ変わり、どの値を比較して、どの条件で終了するかを追えるようにしましょう。
まず線形探索で「順に見る」を理解し、次に二分探索で「半分に絞る」を練習し、最後にハッシュ探索で「位置を計算する」と「衝突」を押さえる流れがおすすめです。
探索アルゴリズムが苦手な人は、いきなり難しいコードを読むより、短い配列を使って手で追うところから始めるとよいです。5個や7個くらいのデータで、目的の値を探し、比較した場所に丸を付けるだけでも十分な練習になります。慣れてきたら、過去問形式の擬似言語で同じことを行いましょう。
最後に、探索は単独で完結するだけでなく、ソート、配列、リスト、ハッシュ表とつながる分野です。この記事で基本の見方を押さえたら、次はソートやデータ構造の問題と合わせて演習してみてください。探索範囲を手で追えるようになると、科目Bのアルゴリズム問題への苦手意識もかなり薄くなるはずです。








コメント